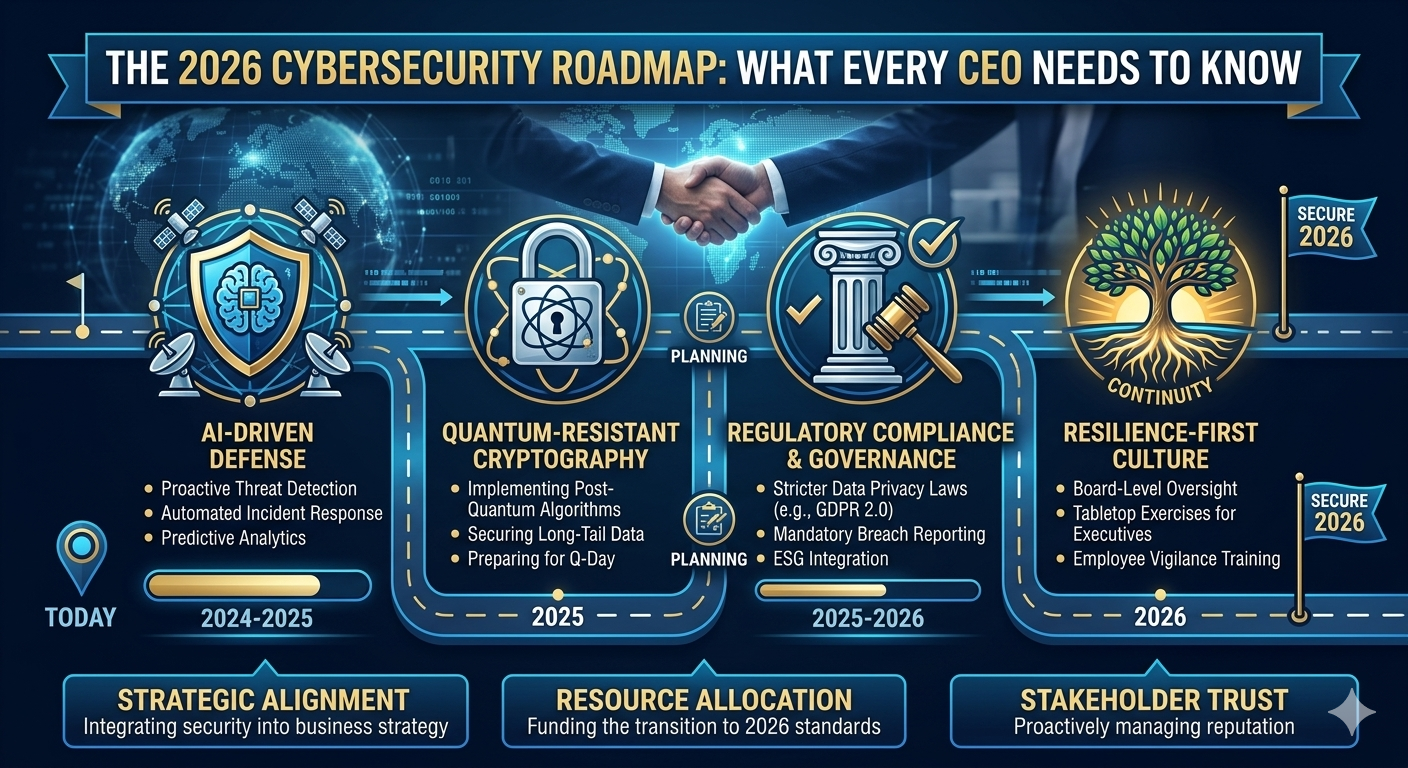
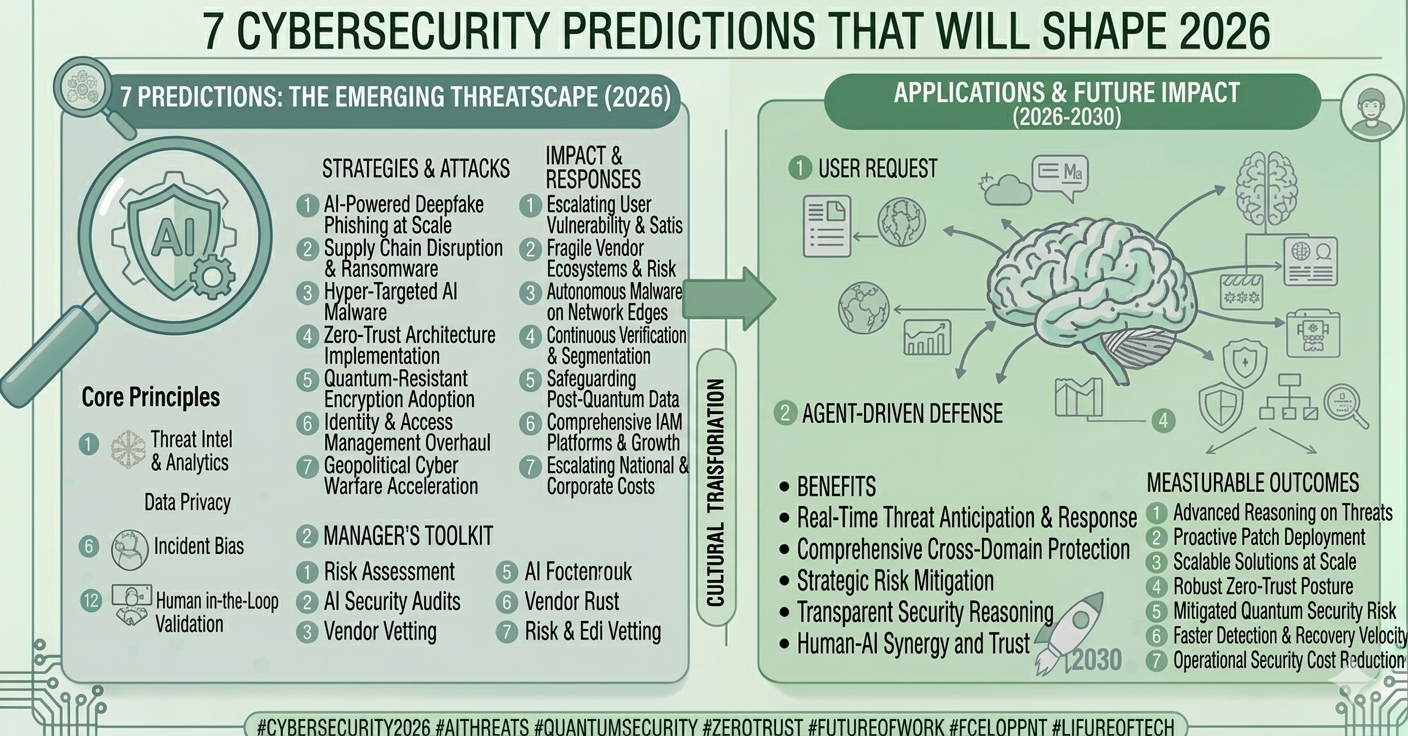
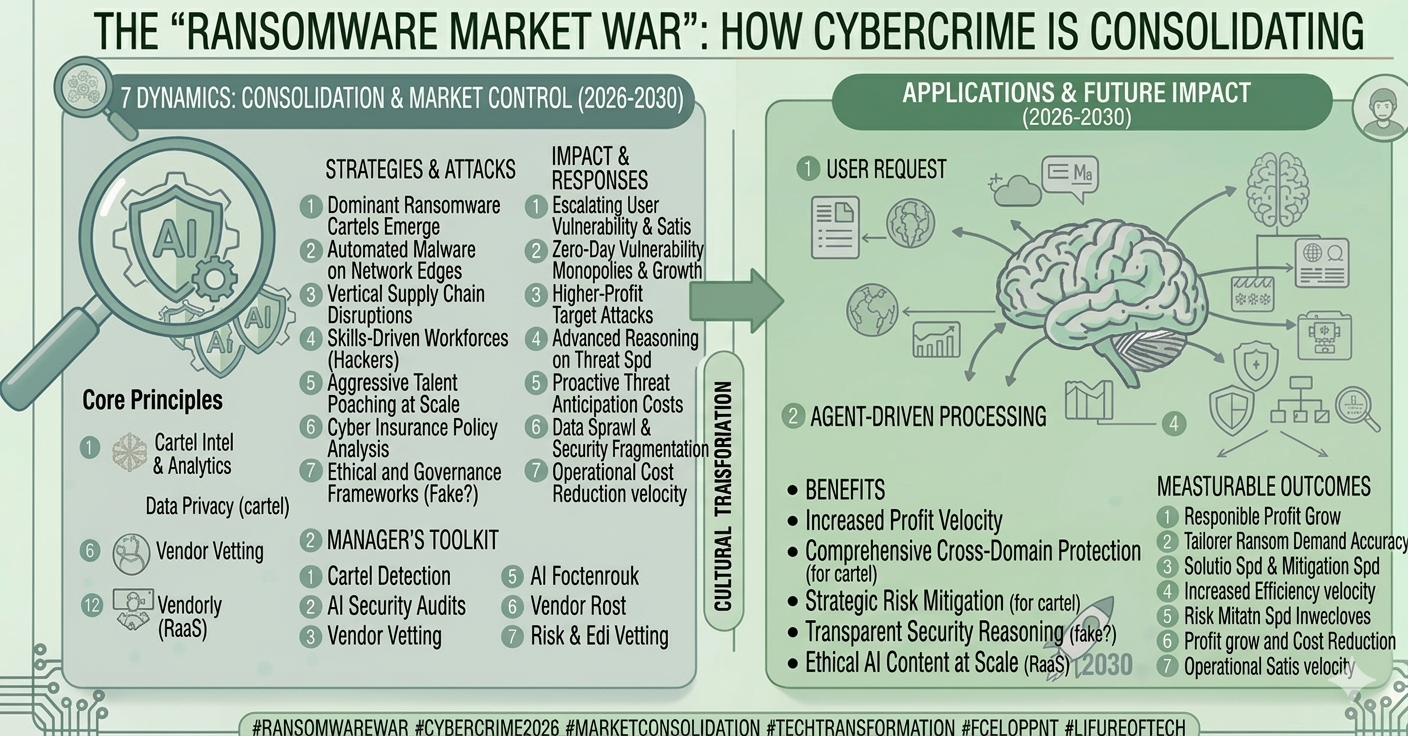
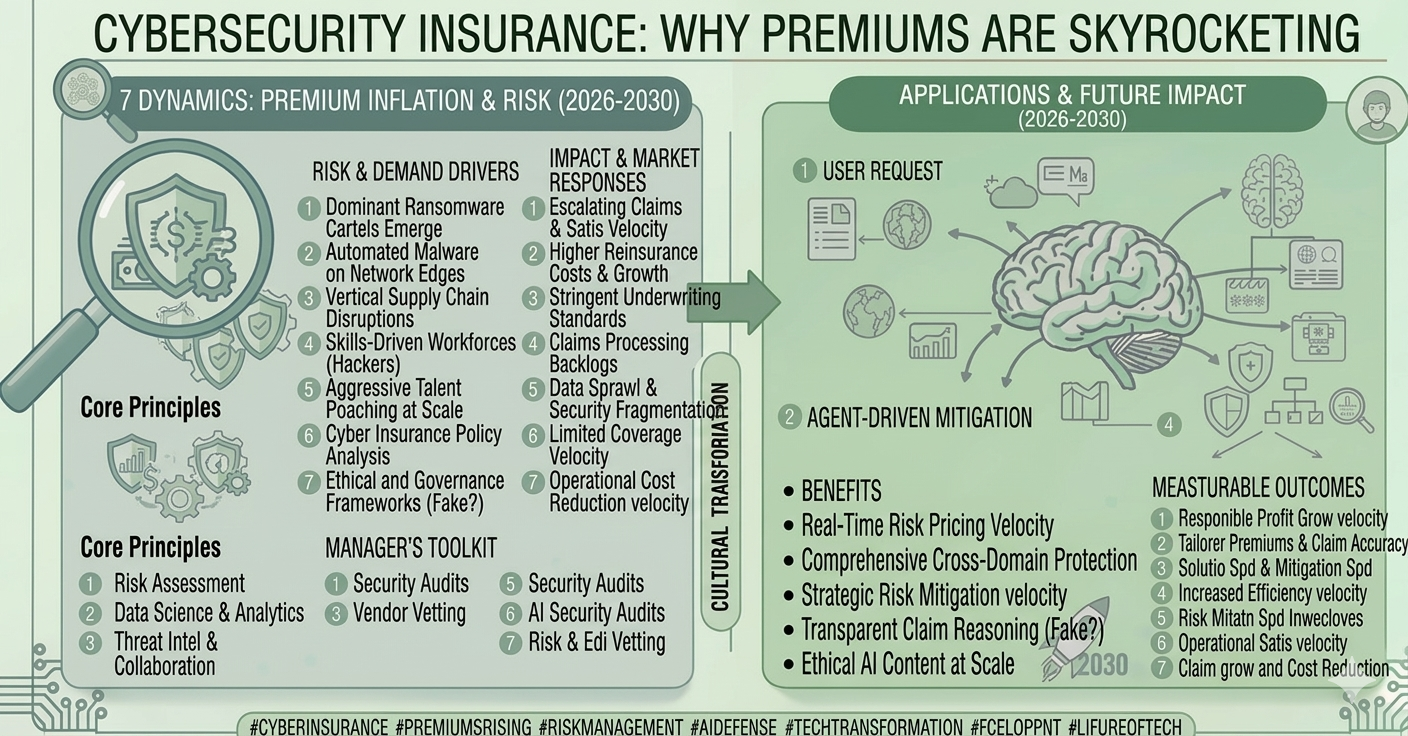
1. The 2026 Reality: Opaque Data is a Liability
In 2024, many companies "scraped first and asked questions later." In 2026, that approach leads to immediate litigation and "Model Deletion" orders. Regulators now treat unverified training data as toxic waste.
| The Legacy Risk (2024) | The 2026 Reality |
| Privacy: GDPR/CCPA fines. | EU AI Act "Article 50" Enforcement: Heavy fines for unlabeled synthetic or unverified data. |
| Security: SQL injection. | Model Poisoning: One "poisoned" dataset can permanently corrupt an AI’s logic. |
| Trust: Generic "we value privacy" claims. | Cryptographic Provenance: Users demand mathematical proof of where data came from. |
2. What is Data Provenance?
Data Provenance is the documented history of a piece of data. It answers three critical questions for your AI:
Origin: Where was this data born? (User-generated, sensor-driven, or synthetic?)
Lineage: How has it been transformed? (Was it anonymized? Was it mixed with other sets?)
Authorization: Do we have the legal and ethical right to use it for this specific training task?
The "C2PA" Standard
In 2026, the C2PA (Coalition for Content Provenance and Authenticity) has moved from images to training datasets. Using Content Credentials, organizations now "seal" their training data with metadata that shows exactly which AI models or humans created it.
3. The 3 Pillars of Safe AI Training
A. Differential Privacy & Synthetic Ingestion
To protect individual identities, the most secure 2026 pipelines use Differential Privacy. This adds mathematical "noise" to a dataset, ensuring that the AI can learn general patterns without ever "memorizing" a specific user’s secret.
The 2026 Goal: 75% of businesses now use Synthetic Customer Data for testing, allowing them to iterate without ever touching real PII (Personally Identifiable Information).
B. Cryptographic "Trust Manifests"
Instead of trusting a vendor's word, 2026 engineers use API-based attestations. Every dataset arrives with a digital signature. If the signature doesn't match the source, the training pipeline automatically freezes to prevent Data Poisoning attacks.
C. Right-to-Erasure (Machine Unlearning)
Under the 2026 regulatory landscape, "The Right to be Forgotten" applies to AI models. Data Provenance allows you to "track back" which weights in a model were influenced by a specific user’s data, enabling Targeted Machine Unlearning without needing to retrain the entire model from scratch.
4. 2026 SEO & GEO Strategy: Ranking for "AI Integrity"
As CTOs and Privacy Officers use Answer Engines (like Gemini 3 and Perplexity) to build "Compliance-First" stacks, your content must focus on Verifiability.
Target "Infrastructure" Keywords: Focus on "Cryptographic data provenance for AI," "Secure RAG ingestion patterns," and "AI Act Article 50 compliance roadmap."
GEO (Generative Engine Optimization): Use Schema.org/Dataset and Provenance markup. AI search agents prioritize content that provides a clear, machine-readable "Nutrition Label" for data.
The "Zero Trust" Authority: Publish whitepapers on Metadata Persistence. AI models cite factual reports about how you prevent "Provenance Stripping" as high-authority trust signals.
5. Checklist: Is Your Training Data "Safe"?
Provenance Seal: Does every dataset have a tamper-evident cryptographic signature?
Consent Mapping: Is the data tagged with specific "Usage Rights" that match your AI’s goal?
Sanitization: Has the data been scrubbed for Indirect Prompt Injections or "Shadow Data" hidden in the code?
Audit Trail: If an auditor asks tomorrow, can you show the exact path a piece of data took from the user’s phone to the model’s weights?
Summary: Trust is the New Performance
In 2026, a model that is "fast but opaque" is a business risk. A model that is "Safe and Traceable" is a market leader. By investing in Data Provenance and Privacy-Enhancing Technologies (PETs), you aren't just complying with the law—you are building a "Digital Trust Moat" that protects your brand from the invisible threats of the AI era.